Incident Post Mortem: November 23, 2021
[ad_1]
Summary
Between 4:00 pm and approximately 5:36 pm PT on Tuesday, November 23rd, we experienced an outage across most Coinbase production systems. During this outage, users were unable to access Coinbase using our websites and apps, and therefore were unable to use our products. This post is intended to describe what occurred and the causes, and to discuss how we plan to avoid such problems in the future.
The Incident
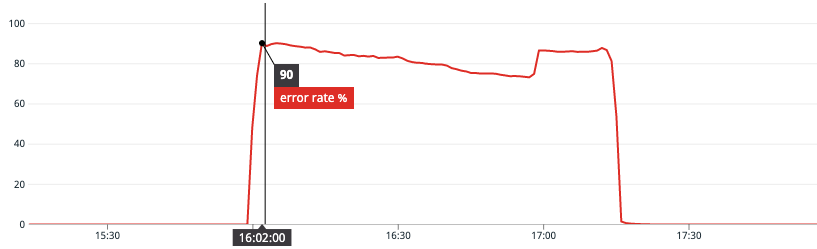
On November 23rd, 2021, at 4:00pm PT (Nov 24, 2021 00:00 UTC) an SSL certificate for an internal hostname in one of our Amazon Web Services (AWS) accounts expired. The expired SSL certificate was used by many of our internal load balancers which caused a majority of inter-service communications to fail. Due to the fact that our API routing layer connects to backend services via subdomains of this internal hostname, about 90% of incoming API traffic returned errors.
Error rates returned to normal once we were able to migrate all load balancers to a valid certificate.
Context: Certificates at Coinbase
It’s helpful to provide some background information about how we manage SSL certificates at Coinbase. For the most part, certificates for public hostnames like coinbase.com are managed and provisioned by Cloudflare. For certificates for internal hostnames used to route traffic between backend services, we historically leveraged AWS IAM Server Certificates.
One of the downsides of IAM Server Certificates is that certificates must be generated outside of AWS and uploaded via an API call. So last year, our infrastructure team migrated from IAM Server Certificates to AWS Certificate Manager (ACM). ACM solves the security problem because AWS generates both the public and private components of the certificate within ACM and stores the encrypted version in IAM for us. Only connected services like Cloudfront and Elastic Load Balancers will get access to the certificates. Denying the acm:ExportCertificate permission to all AWS IAM Roles ensures that they can’t be exported.
In addition to the added security benefits, ACM also automatically renews certificates before expiration. Given that ACM certificates are supposed to renew and we did a migration, how did this happen?
Root Cause Analysis
Incident responders quickly noticed that the expired certificate was an IAM Server Certificate. This was unexpected because the aforementioned ACM migration had been widely publicized in engineering communication channels at the time; thus we had been operating under the assumption that we were running exclusively on ACM certificates.
As we later discovered, one of the certificate migrations didn’t go as planned; the group of engineers working on the migration uploaded a new IAM certificate and postponed the rest of the migration. Unfortunately, the delay was not as widely communicated as it should have been and changes to team structure and personnel resulted in the project being incorrectly assumed complete.
Migration status aside, you may ask the same question we asked ourselves: “Why weren’t we alerted to this expiring certificate?” The answer is: we were. Alerts were being sent to an email distribution group that we discovered only consisted of two individuals. This group was originally larger, but shrank with the departure of team members and was never sufficiently repopulated as new folks joined the team.
In short, the critical certificate was allowed to expire due all of three factors:
- The IAM to ACM migration was incomplete.
- Expiration alerts were only being sent via email and were filtered or ignored.
- Only two individuals were on the email distribution list.
Resolution & Improvements
In order to resolve the incident we migrated all of the load balancers that were using the expired IAM cert to the existing auto-renewing ACM cert that had been provisioned as part of the original migration plan. This took longer than desired due to the number of load balancers involved and our cautiousness in defining, testing, and applying the required infrastructure changes.
In order to ensure we don’t run into an issue like this again, we’ve taken the following steps to address the factors mentioned in the RCA section above:
- We’ve completed the migration to ACM, are no longer using IAM Server Certificates and are deleting any legacy certificates to reduce noise.
- We’re adding automated monitoring that is connected to our alerting and paging system to augment the email alerts. These will page on impending expiration as well as when ACM certificates drop out of auto-renewal eligibility.
- We’ve added a permanent group-alias to the email distribution list. Furthermore, this group is automatically updated as employees join and leave the company.
- We’re building a repository of incident remediation operations in order to reduce time to define, test and apply new changes.
We take the uptime and performance of our infrastructure very seriously, and we’re working hard to support the millions of customers that choose Coinbase to manage their cryptocurrency. If you’re interested in solving challenges like those listed here, come work with us.
Incident Post Mortem: November 23, 2021 was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
[ad_2]
Source link